The NVIDIA GTC Spring 2023 Keynote Live Blog (8:00am PT/15:00 UTC)
by Ryan Smith on March 21, 2023 8:00 AM EST- Posted in
- Live Blog
- GPUs
- Trade Shows
- NVIDIA
- Keynote
- Grace
- Hopper
- Ada Lovelace

10:57AM EDT - Welcome to our live blog coverage of NVIDIA’s Spring GTC 2023 keynote address
10:58AM EDT - The traditional kick-off to the show – be it physical or virtual – NVIDIA’s annual spring keynote is showcase for NVIDIA’s vision for the next 12 to 24 months across all of their segments, from graphics to AI to automotive. Along with a slew of product announcements, the presentation, delivered by CEO Jensen Huang always contains a few surprises
10:58AM EDT - Looking at NVIDIA's sizable product stack, NVIDIA is coming off of the launch of their new Hopper and Ada Lovelace GPU architectures for servers and clients respectively. But there are plenty of spots for individual products that remain to be filled. Meanwhile, NVIDIA expects to release their long-awaited Grace CPU this year, and while many of the technical details of that Armv9-based core have since been released, we should hopefully get some launch details for that. As well as its combined CPU+GPU counterpart, Grace Hopper, which places the Grace CPU and Hopper GPU on the same package.
10:58AM EDT - Meanwhile, we're expecting NVIDIA to take a small victory lap at this year's GTC for having the uncanny timing in launching Hopper and its large language model-friendly Transformer Engines right as the market for GPT and other LLMs has exploded. Now it will be interesting to see how NVIDIA intends to further grow (and profit from) those businesses. The company has all but promissed investors that a cloud service play of some kind will be announced at this GTC.
10:59AM EDT - At this point we're just waiting for the keynote stream to kick off, which should be promptly at 8am
11:00AM EDT - NVIDIA's GTC conference is, bucking the trends, remaining a virtual conference this year
11:01AM EDT - And here we go

11:01AM EDT - Jensen is immediate diving into the subjects of accelerated computing and AI
11:02AM EDT - New advances in NVIDIA's full stack of services
11:02AM EDT - "Welcome to GTC"
11:02AM EDT - Welcoming more than 250K people to this year's virtual conference
11:02AM EDT - 4 years ago the last in-person conference had 8K attendees

11:03AM EDT - "650 amazing talks"
11:04AM EDT - And quickly covering a list of subjects covered in this year's talks


11:05AM EDT - "The purpose of GTC is to inspire the world on the art of what's possible with accelerated computing"
11:05AM EDT - Now rolling NVIDIA's latest "I am AI" video


11:08AM EDT - And, of course, NVIDIA has used AI to put together parts of this video (as they have done for a couple of years now)
11:08AM EDT - "Accelerated computing is not easy"

11:09AM EDT - Accelerated applications can enjoy speed ups and scale ups across many systems
11:09AM EDT - Giving a 1 million-fold increase in performance over the last decade in certain tasks


11:10AM EDT - Using then-and-now comparison of AlexNet and GPT-3 as a comparison of the number of FP operations required to train the respective neural nets
11:10AM EDT - And of course, GPT is all the rage now
11:11AM EDT - "Several thousand applications aare now NVIDIA accelerated"
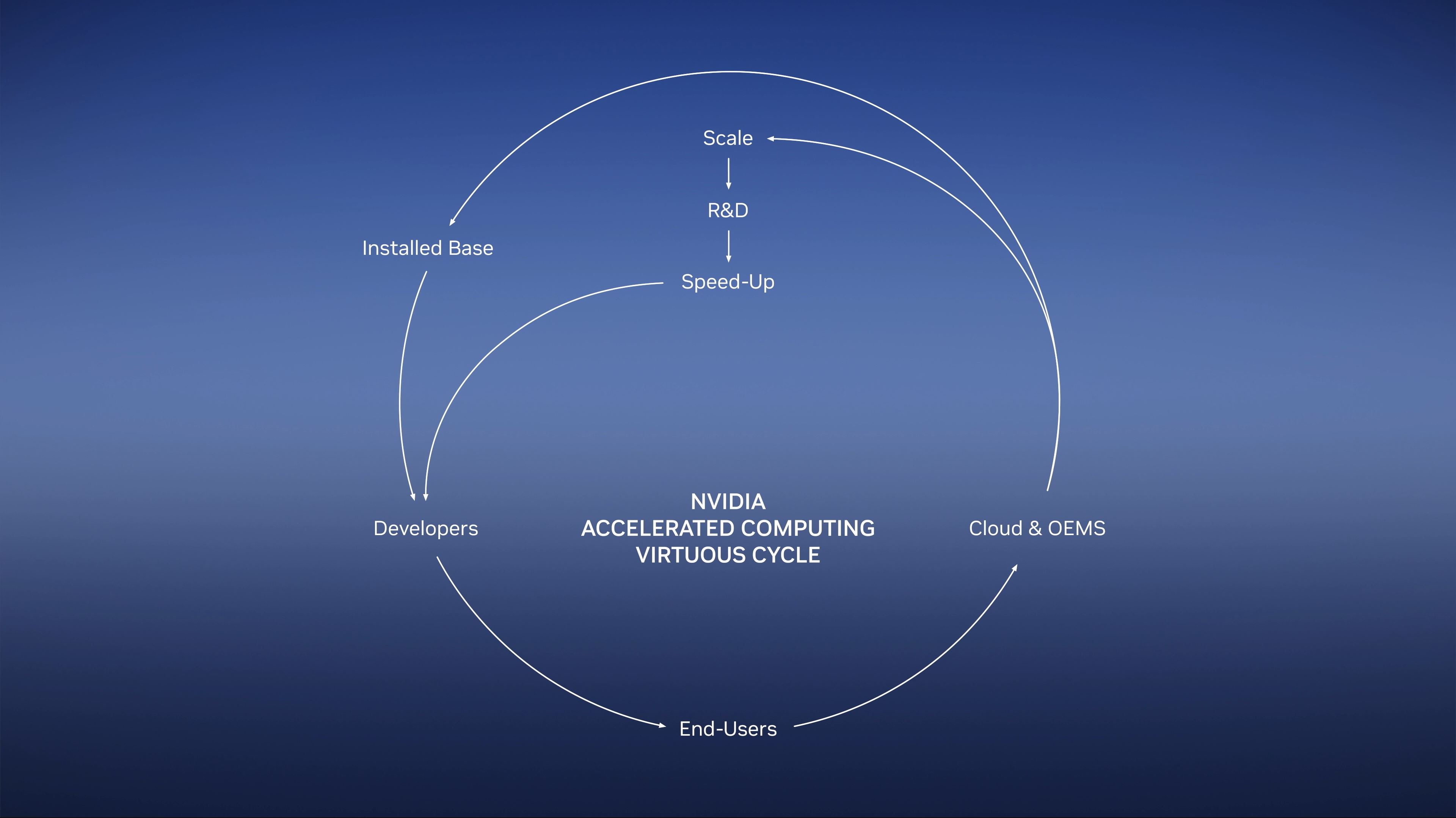
11:11AM EDT - And NVIDIA has established a cycle of users, applications, and developers to make an active ecosystem
11:12AM EDT - A big part of laying this groundwork has been NVIDIA providing so many libraries for different tasks
11:12AM EDT - Jensen is going through some of those libraries now

11:13AM EDT - NVIDIA is continuing their work with quantum computing and their cuQuantum library

11:13AM EDT - Which is being used to help simulate quantum computers
11:14AM EDT - Today NVIDIA is announcing a quantum control link which allows connecting NV GPUs to quantum computers for error correction (of the quantum computer)

11:15AM EDT - Now on to Spark RAPIDS and vector databases
11:15AM EDT - Introducing a new library: RAFT

11:16AM EDT - For further accelerating vector databases
11:17AM EDT - (As a general reminder, NVIDIA has more software engineers than it does hardware engineers. So new software is a huge part of their total body of work. It also means that software is a huge part of GTC presentations these days)
11:18AM EDT - Jensen is highlighting NVIDIA's partnership with AT&T, which is using NV tech for everything from 5G planning to Riva for voice synthesis

11:18AM EDT - Now talking about NVIDIA's inference platform, recapping TensorRT, Triton, and TMS
11:19AM EDT - New features include multi-GPU, multi-node inference for GPT large language models

11:20AM EDT - Now on to GPU video processing. CV-CUDA and VPF
11:20AM EDT - Microsoft, Tencent, and others are using these libraries to process hundreds of thousands of videos per day
11:21AM EDT - Video processing is a major processing consumer, as a result. Making it a good target for optimization and acceleration
11:21AM EDT - Next up: Genomics
11:21AM EDT - Including NVIDIA Parabricks

11:21AM EDT - Announcing Parabricks 4.1 today
11:22AM EDT - And Holoscan, NV's library for real time medical image processing

11:22AM EDT - And NVIDIA is partnering with Medtronic to develop a common AI platform
11:23AM EDT - Now on to chip manufacturing
11:23AM EDT - Jensen is talking about the extremely small scale of silicon lithography today

11:23AM EDT - Litho is an imaging problem at the edge of physics
11:24AM EDT - Recapping how EUV litho works. And how much it costs - over $250M


11:24AM EDT - As well as how interference patterns within the EUV light is used to create patterns smaller than the light
11:24AM EDT - Computational lithography

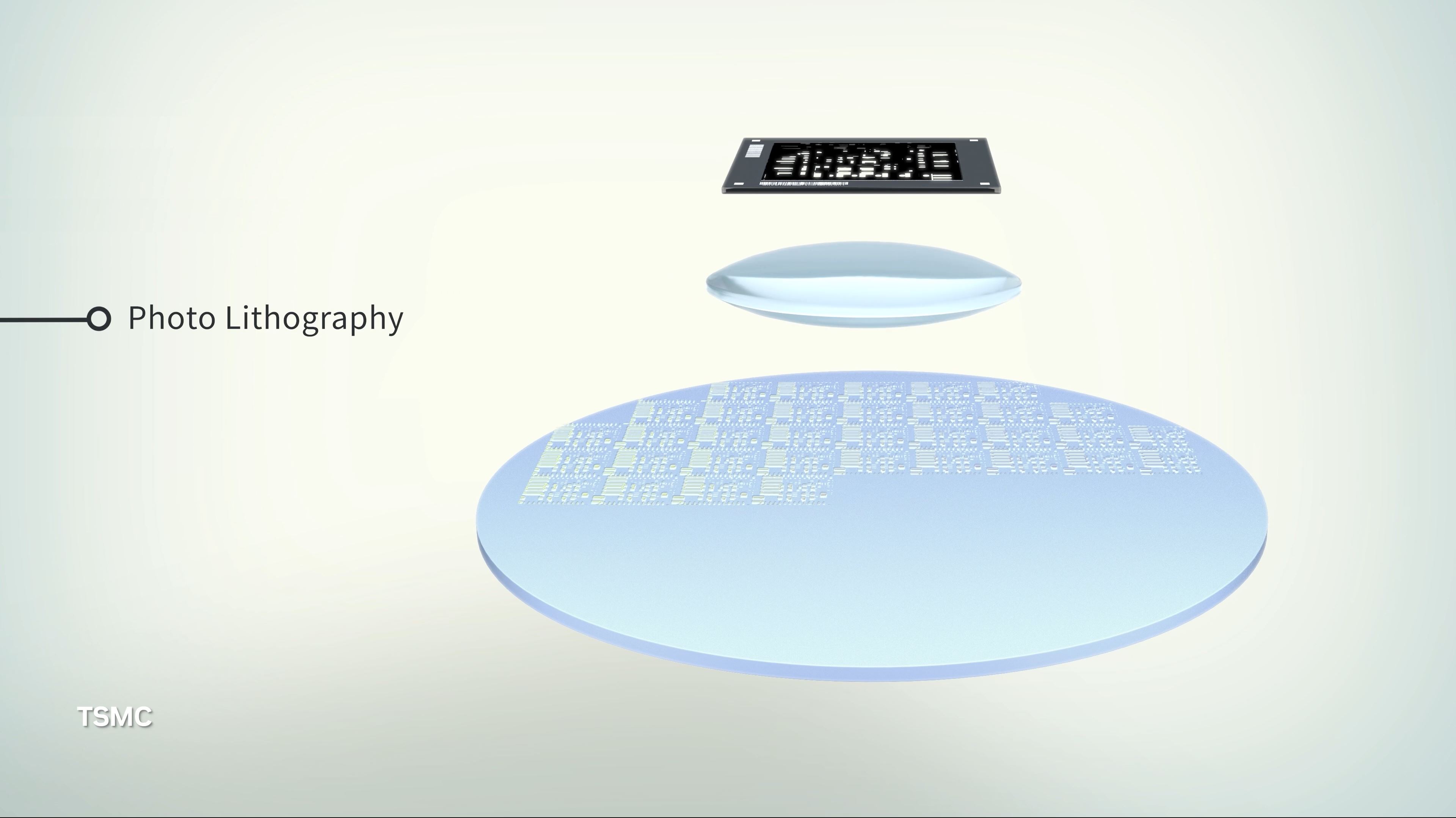
11:25AM EDT - Simulating Maxwell's equations to develop and refine litho masks
11:25AM EDT - Computational lithography use is growing fast
11:26AM EDT - New library: cuLitho, to accelerate computational lithography by over 40x
11:26AM EDT - A single reticle currently takes 2 weeks to process. cuLitho can do it in an 8 hour shift
11:26AM EDT - cuLitho can also reduce power consumption by reducing the number of systems required
11:27AM EDT - TSMC will be qualifying cuLitho for production starting in June
11:27AM EDT - Now on to cloud computing
11:28AM EDT - Increasing computing needs are being capped by data center physical power limits, not to mention a desire to cut back on power consumption for environmental reasons
11:28AM EDT - Looks like this will be about NV's Grace CPU
11:28AM EDT - Grace excels where GPUs do not - single threaded serial processing

11:28AM EDT - 72 Arm cores with a 3.2TB/sec fabric

11:29AM EDT - Grace superchip is 2 Graces on a single board

11:29AM EDT - Grace Superchip module
11:29AM EDT - 5 x 8 inches

11:30AM EDT - 2 Grace Superchip modules can fit in a single air-cooled 1U server rack

11:30AM EDT - Claiming 2x the perf at iso-power
11:31AM EDT - Grace is sampling now
11:31AM EDT - And NVIDIA's partners are working to assemble systems
11:31AM EDT - Now on to NVIDIA's networking hardware business
11:31AM EDT - BlueField-3 is in production

11:32AM EDT - That's NVIDIA's latest-generation DPU
11:32AM EDT - Now on to NVIDIA DGX

11:32AM EDT - Half of Fortune 100 companies have installed DGX

11:33AM EDT - Recapping DGX topology and features

11:33AM EDT - DGX H100 is now in full production (now that Intel is finally shipping Sapphire Rapids in volume)
11:34AM EDT - And public cloud providers, including Microsoft's Azure, are quickly adopting DGX for their services
11:34AM EDT - "DGX supercomputers are modern AI factories"
11:34AM EDT - "Generative AI has triggered a sense of urgency to develop AI strategies"
11:34AM EDT - Announcing NVIDIA DGX Cloud

11:35AM EDT - So here's NVIDIA's big cloud services announcement
11:35AM EDT - NVIDIA's ecosystem available via DGX systems hosting cloud instances at the public cloud providers
11:35AM EDT - "Cloud extension of our business model"
11:36AM EDT - Oracle Cloud Infrastructure will be the first DGX public cloud service
11:36AM EDT - 50 early access customers across several industries
11:36AM EDT - Now on to generative AI and its recent explosion
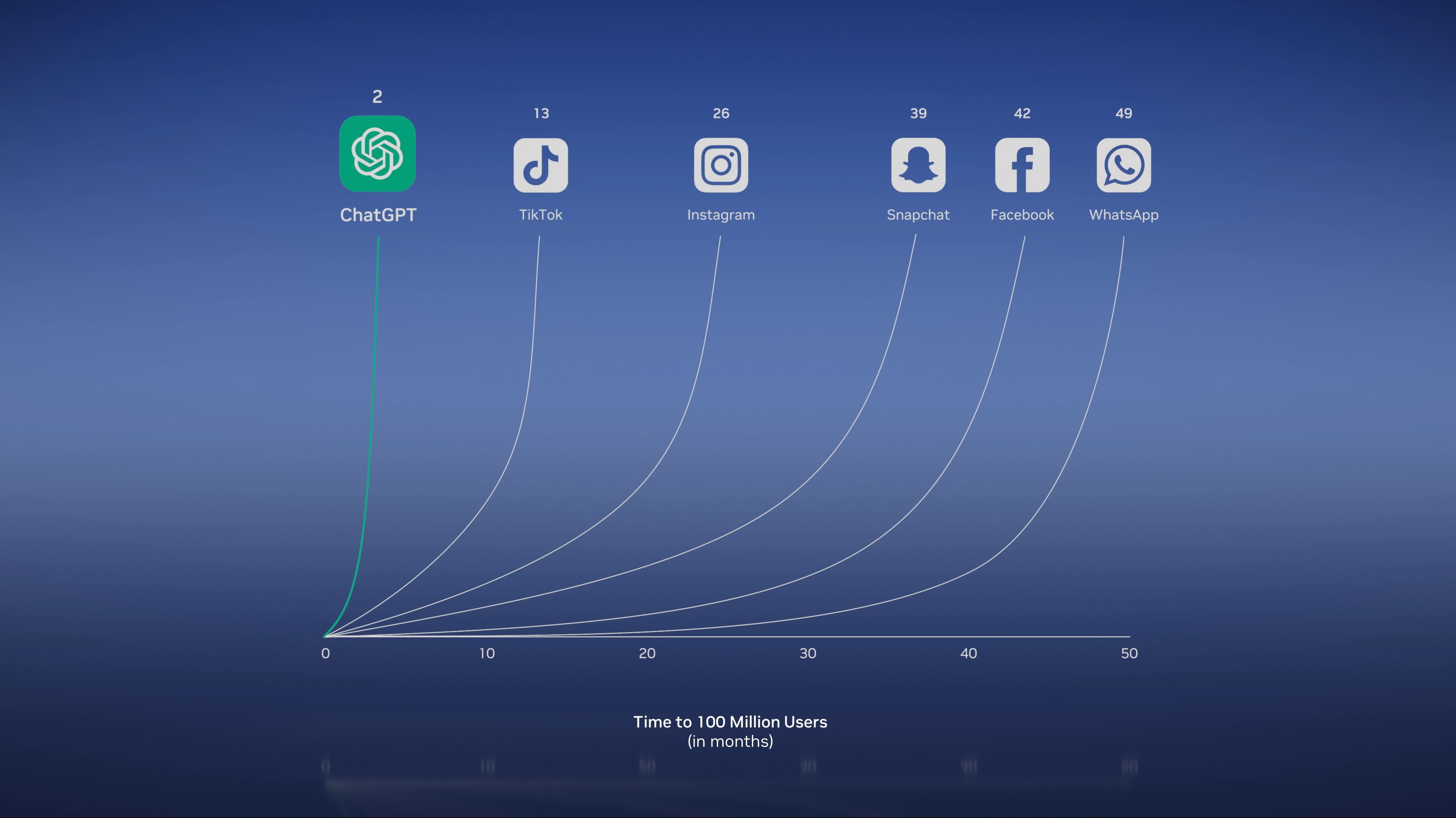
11:37AM EDT - (GPT is going to sell a massive number of H100s at this rate...)
11:38AM EDT - Jensen is recapping large language models and the many things that can be done with GPT and other LLMs, such as generating text and images
11:38AM EDT - "Generative AI is a new kind of computer, one we program in human language"
11:38AM EDT - "Now, everyone is a programmer"
11:39AM EDT - Comparing generative AI to whole platforms such as the PC
11:39AM EDT - Now quickly talking about the many services using generative AI in some form or another
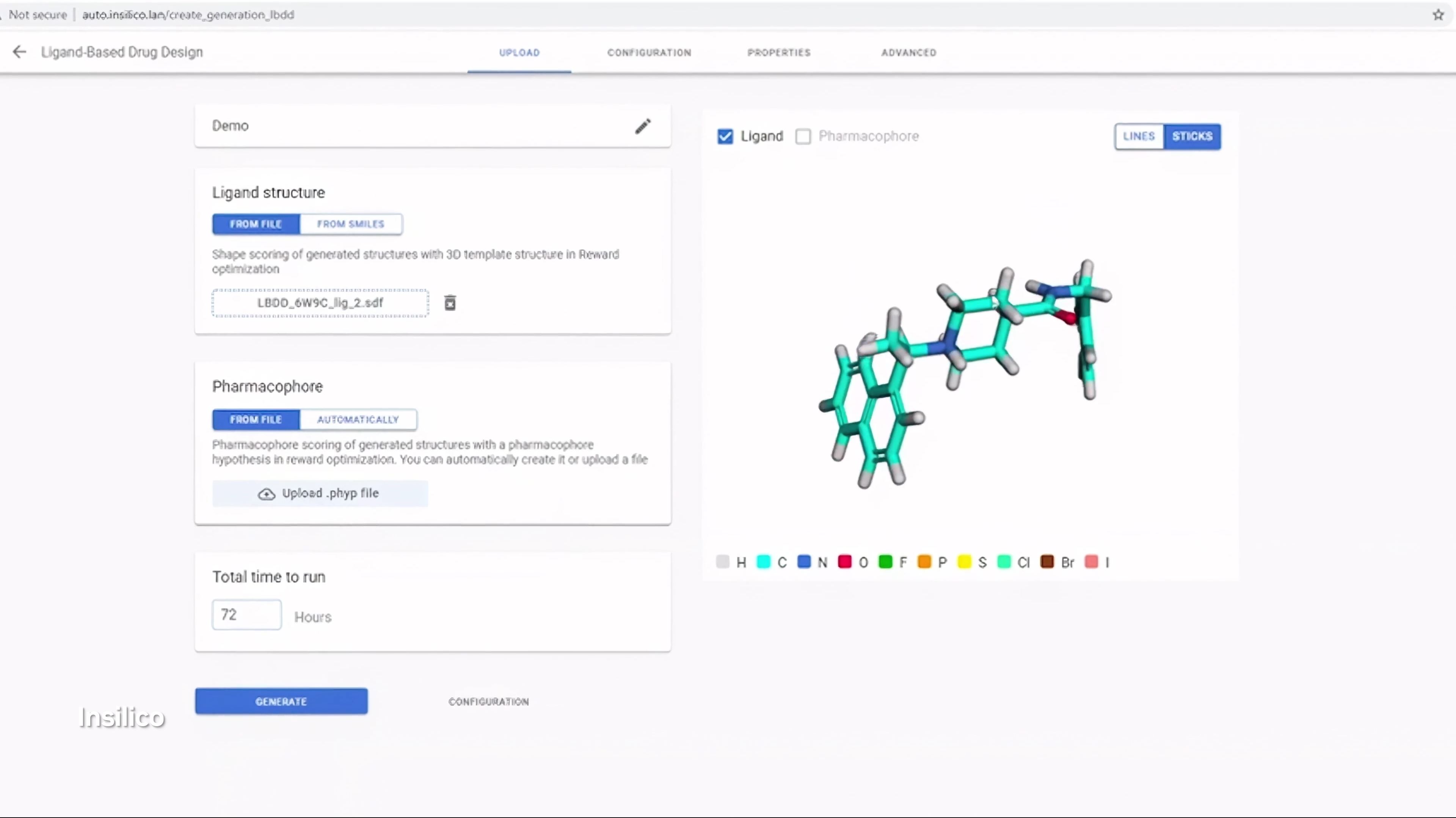
11:39AM EDT - Even accelerated drug design
11:40AM EDT - "The industry needs a foundry. A TSMC for large language models"

11:40AM EDT - Announcing NVIDIA AI Foundations
11:40AM EDT - Language, visual, and biology model making services
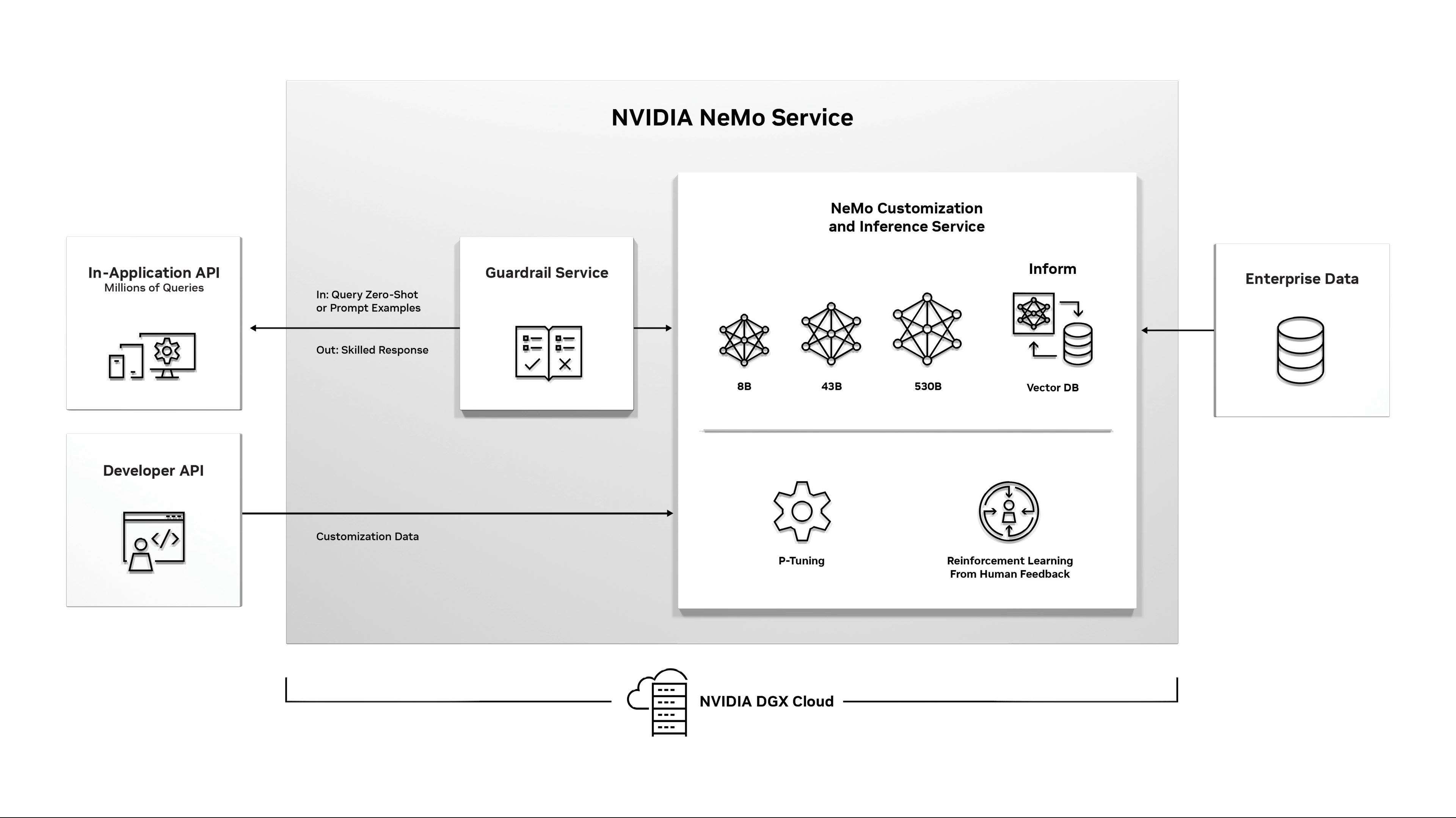
11:41AM EDT - Using NVIDIA NeMo, Picasso, and BioNeMo respectively
11:41AM EDT - Customers can create their own models or start with one of NVIDIA's pre-trained models and customize from there
11:42AM EDT - Now rolling a video about AI Foundations and how it works
11:42AM EDT - (This is moving far too quickly to recap it all)
11:43AM EDT - Reinforcement learning used in NeMo to further improve its performance and accuracy
11:43AM EDT - "A personalized, AI model that you control"
11:43AM EDT - That was a video on NeMo. Now we're on to a video about Picasso
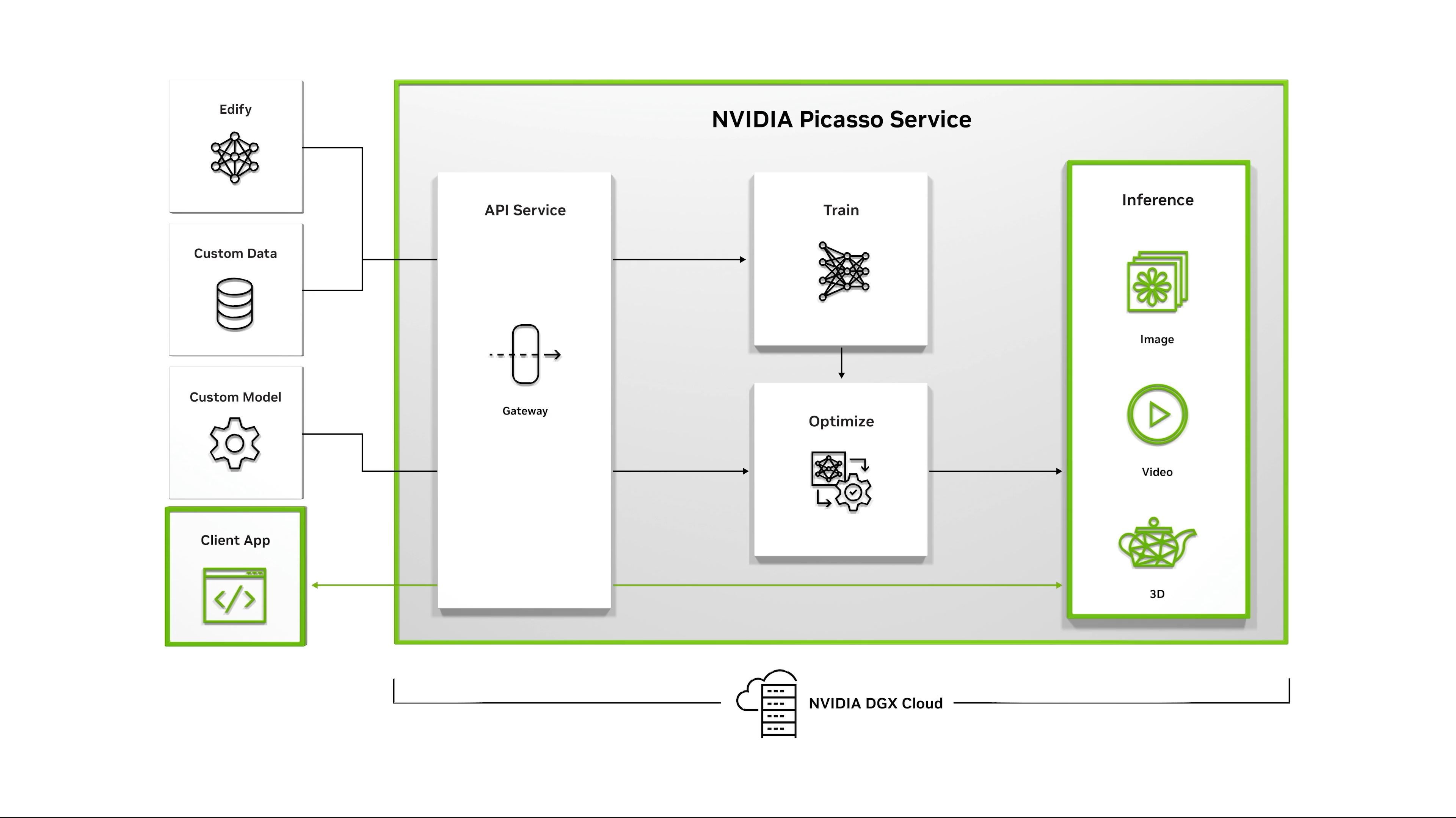
11:44AM EDT - Picasso is a service for generating images, video, and models
11:45AM EDT - Getty Images will be using the Picasso service, trained on their library of legally licensed images
11:45AM EDT - Shutterstock will be doing something similar
11:46AM EDT - Announcing a significant expansion of the Adobe partnership to build a set of next-gen AI capabilities into Adobe's software
11:46AM EDT - Adobe Generative Images
11:47AM EDT - And Adobe's Content Authenticity Initiative
11:47AM EDT - Now on to BioNeMo - generative AI for biology
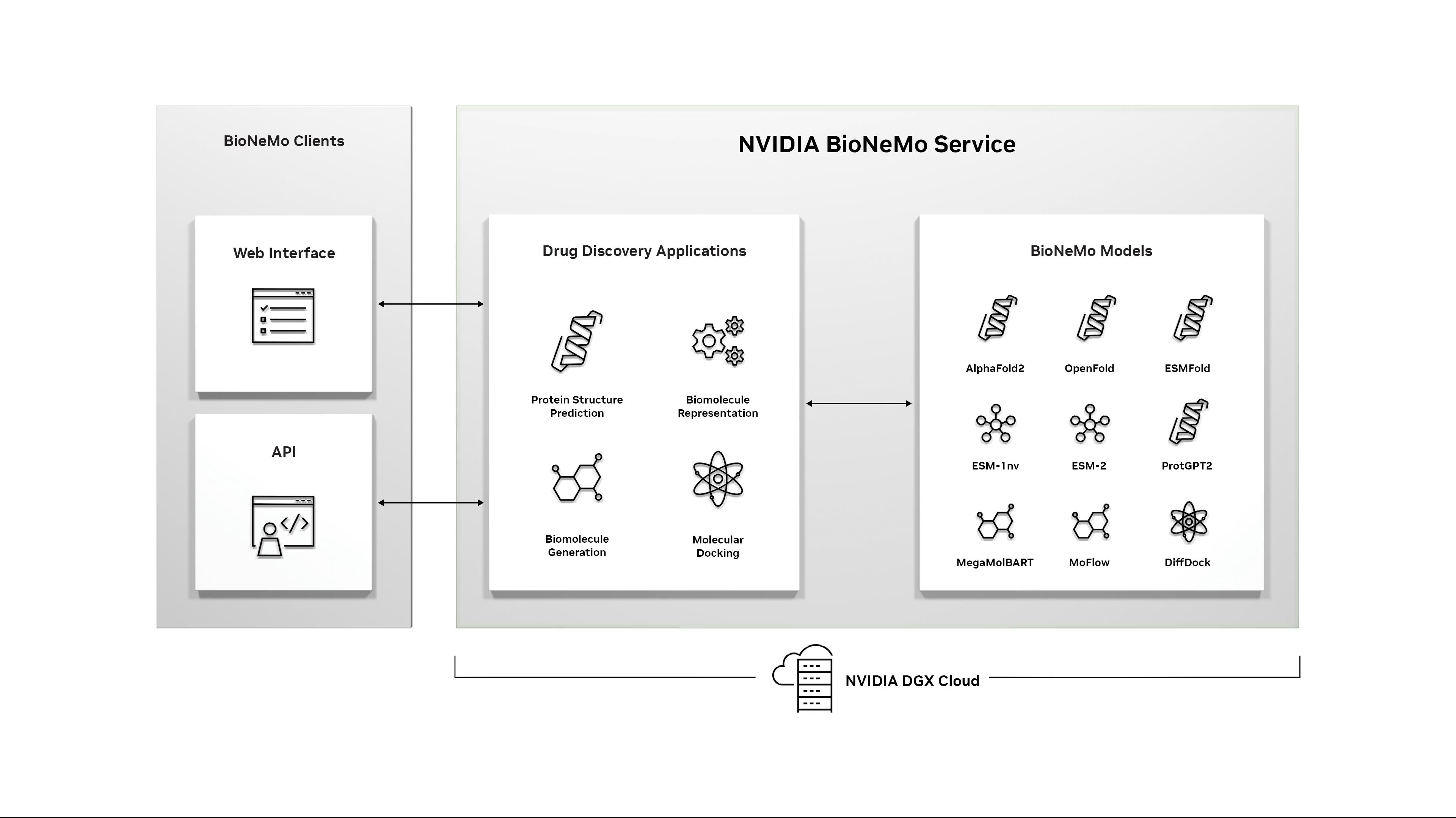
11:48AM EDT - BioNeMo provides models for drug discovery
11:48AM EDT - Protien folding, molecule generation, etc
11:49AM EDT - Accurately predict the structure of a protein in seconds
11:50AM EDT - And that's NVIDIA AI Foundations
11:50AM EDT - Now on to automotive
11:51AM EDT - No, my bad. Now on to talking about data center construction
11:51AM EDT - "No one accelerator can optimally process" the wide variety of models
11:51AM EDT - New inference platform: 4 configurations, 1 architecture, 1 software stack
11:51AM EDT - New product: L4 acceleraetor card. Replaces T4
11:52AM EDT - Want to use L4 to replace CPU servers for AI video processing
11:52AM EDT - Google is offering L4 on Google Cloud
11:53AM EDT - Google GCP is now a premiere NVIDIA AI cloud

11:53AM EDT - More info on that to come later on
11:54AM EDT - L40 accelerator card. This is more of a recap, as the product was released last year
11:54AM EDT - The L series being NVIDIA's designation for server cards based on the Ada Lovelace architecture
11:55AM EDT - L40 is more aimed at image processing/generation, and is the backbone of NVIDIA's Omniverse/OVX hardware
11:55AM EDT - Large language models live up to the name. GPT can get extremely large
11:55AM EDT - Announcing H100 NVL

11:56AM EDT - Dual card/quad slot PCIe product. 2 GH100s with 94GB of memory each
11:56AM EDT - And then Grace Hopper

11:57AM EDT - Grace CPU + Hopper GPU on a single board, for tasks that need both types of processing

11:57AM EDT - CPU/GPU interface 7x faster than PCIe
11:58AM EDT - A bit aspirational at this second, as Grace Hopper is not yet shipping
11:58AM EDT - And that's NVIDIA's AI hardware
11:59AM EDT - Now on to Omniverse
11:59AM EDT - Rolling a video of how Amazon's robotics arm is using Omniverse

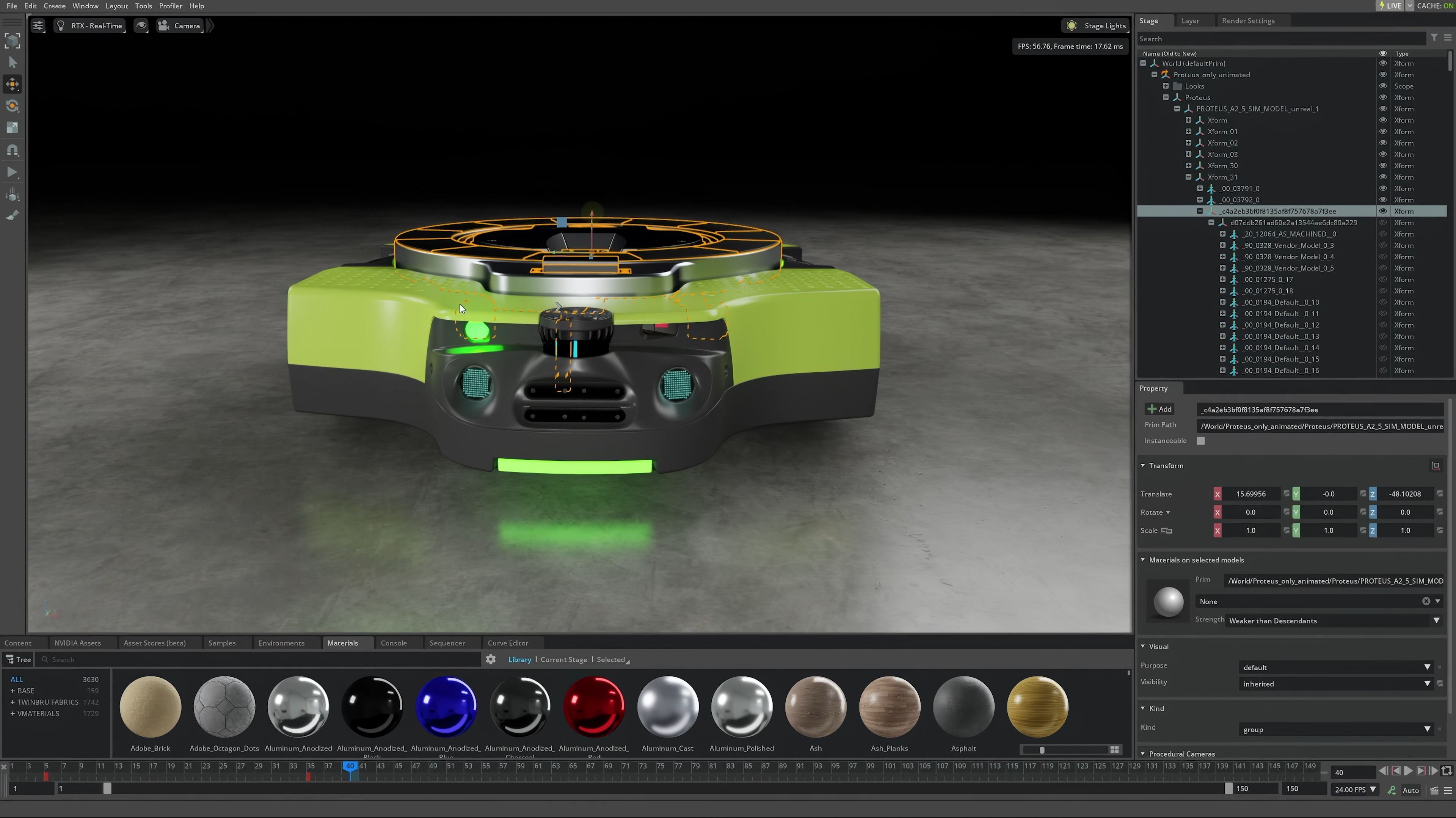
12:00PM EDT - Using Isaac Sim to develop the technology

12:01PM EDT - And using simulations to train their models faster
12:02PM EDT - Once again promoting Omniverse and its use of the USD file format
12:02PM EDT - NV has made significant updates to Omniverse in every area
12:02PM EDT - Now rolling a highlight video
12:03PM EDT - DRIVE Sim, Replicator, PhysX Flow, Warp, multi-GPU/multi-node support, Isaac Sim, SimReady Assets, Replicator, Audio2Face, Neural Materials, and more

12:04PM EDT - "Nearly 300K creators and designers have downloaded Omniverse"
12:05PM EDT - Lising numerous new CAD/CAM applications that are now plugged in to Omniverse


12:07PM EDT - And listing off the many companies using Omniverse in some fashion and how they're using it. A lot of manufacturers, to say the least
12:07PM EDT - BMW is building a factory virtually first, 2 years before they build the actual thing

12:09PM EDT - Demoing how a virtual planning session goes
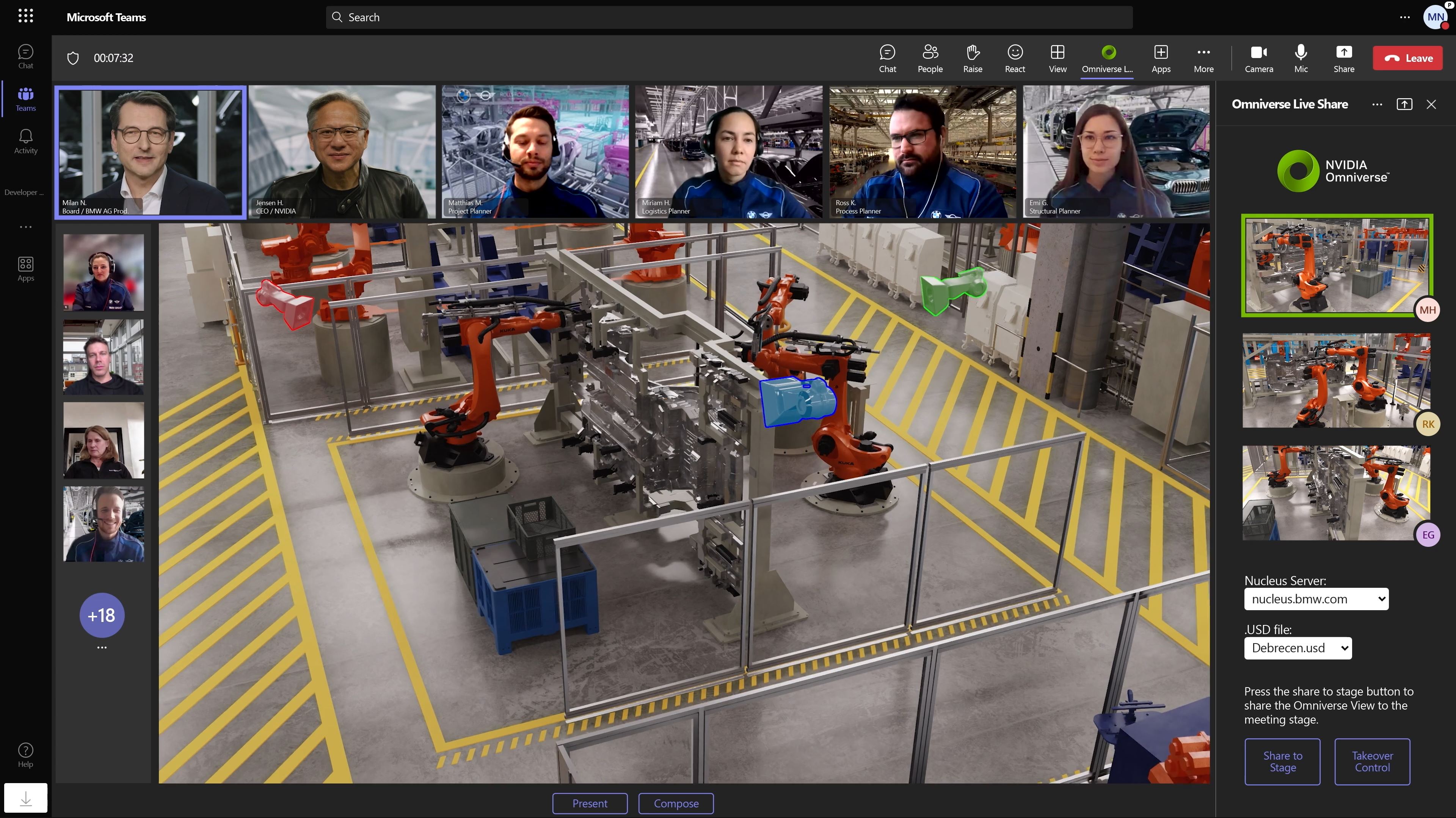
12:09PM EDT - Using Microsoft Teams and Omniverse

12:10PM EDT - Announcing 3 systems to run Omniverse
12:11PM EDT - New generation of workstations powered

12:11PM EDT - New OVX 3.0 servers

12:11PM EDT - And #3: NVIDIA Omniverse Cloud
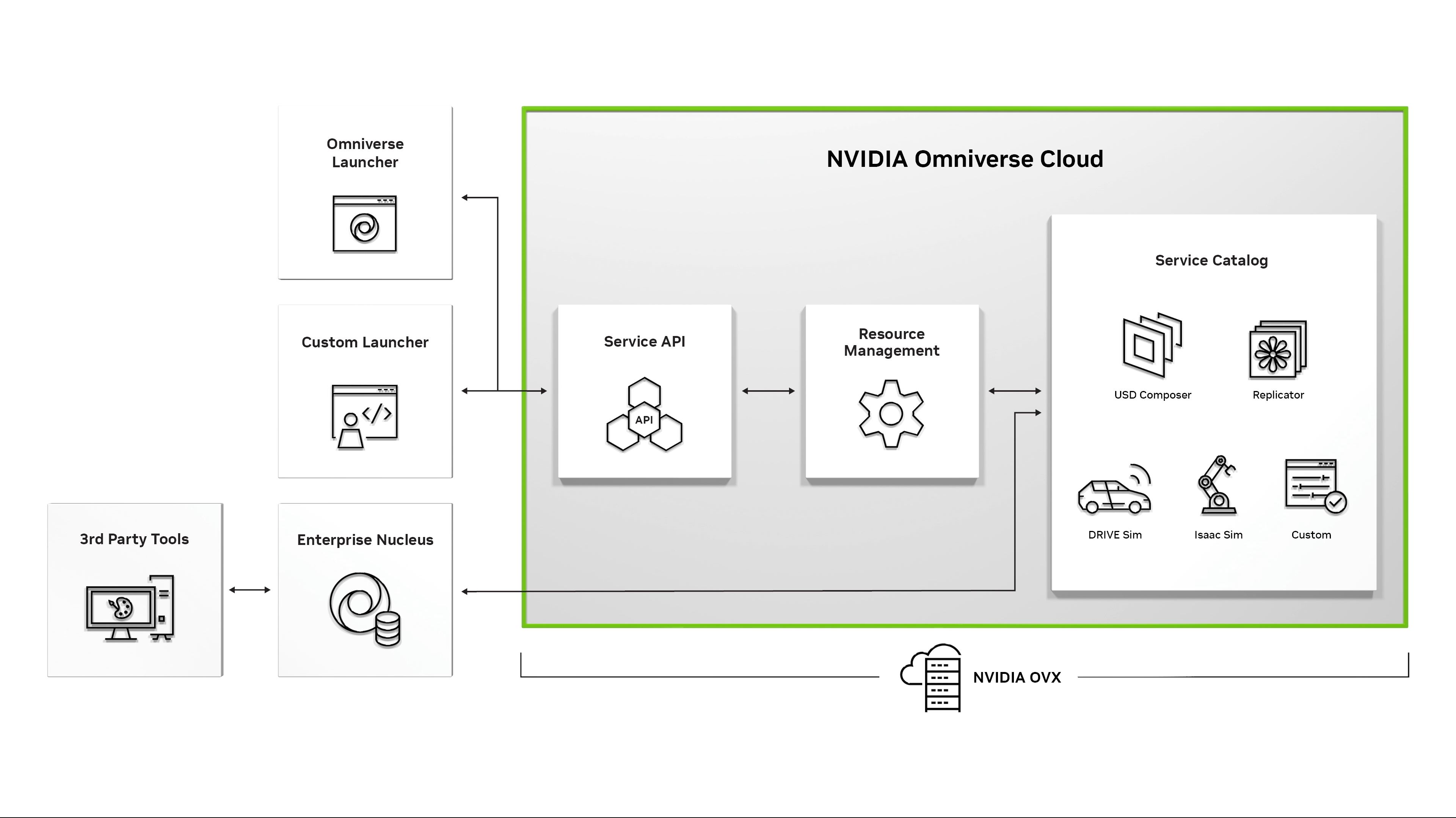
12:12PM EDT - Omniverse running on cloud services
12:13PM EDT - A fuily-managed cloud service. Partnering with Microsoft, to be hosted on Azure

12:14PM EDT - Connecting Omniverse Cloud to Microsoft's 365 services
12:14PM EDT - Bringing Omniverse to millions of 365 and Azure users
12:15PM EDT - Now recapping the keynote
12:15PM EDT - New hardware, new libraries, and more

12:16PM EDT - Extending business model with NVIDIA DGX Cloud
12:16PM EDT - Best of NVIDIA at best of world's leading CSPs
12:17PM EDT - And NVIDIA AI Foundations for model making services
12:17PM EDT - Plus numerous Omniverse upgrades, and Omniverse cloud services
12:18PM EDT - Jensen is now thanking NVIDIA's partners and employees

12:18PM EDT - And that's a wrap! Please check out our individual articles on NVIDIA's new hardware announcements
12:18PM EDT - https://www.anandtech.com/show/18780/nvidia-announces-h100-nvl-max-memory-server-card-for-large-language-models
12:19PM EDT - https://www.anandtech.com/show/18781/nvidia-unveils-rtx-ada-lovelace-gpus-for-laptops-desktop-rtx-4000-sff








18 Comments
View All Comments
James5mith - Tuesday, March 21, 2023 - link
"Oh such unprecedented demand. The best we can possibly do is to only raise prices by 20% on the consumer side. Otherwise the company would go bankrupt..."Gothmoth - Tuesday, March 21, 2023 - link
ngreedia can go and FO! despicable company....milleron - Tuesday, March 21, 2023 - link
It would be very funny if it weren't so true.SystemsBuilder - Tuesday, March 21, 2023 - link
Shameless marketing at it's best.He was aggressively pushing Nvidia's products for AI all over the place today. like everywhere. only though they missed to mention was world peace.
Remember how hard they pushed their products for crypto just a few year(s) ago.
Not one single word about crypto today.
No credibility. None! Zero!
lilkwarrior - Tuesday, March 21, 2023 - link
…Your lack of business acumen is showing. A good business–similarly to a person who manages their skillset in the open market well–aligns the times, the state of the market, and the most lucrative demands most sensible to what they bring to the table.Nvidia nor any company cares about sticking to a audience base if it doesn't serve them to make the most revenue or keep the doors open anymore.
SystemsBuilder - Tuesday, March 21, 2023 - link
I can assure you there is nothing wrong with my business acumen. Decades of business management experience severs me very well in my assessment of Nivdia above. Expecting customers and partners to forget everything from last year(s) and fully embrace this years slogans.But likely, you are a Nvidia marketer or similar, so I bet we will not get a lot of self assessment or, god forbid, self criticism. Market Management by slogans comes to mind, using terms like "this years strategy" and other oxymorons. If you need further clarification, I advice you to go back to business school and read Porter all over again.
Gothmoth - Wednesday, March 22, 2023 - link
no shit sherlock....but there are some companys an then there is ngreedia.
lemurbutton - Tuesday, March 21, 2023 - link
They never pushed their products for crypto.mode_13h - Thursday, March 23, 2023 - link
Um, they had an entire product line of crypto-focused cards!edzieba - Wednesday, March 22, 2023 - link
"Remember how hard they pushed their products for crypto just a few year(s) ago."If by "pushed hard" you mean never mentioned it in a keynote or other presentation, tried (though failed) to limit its use in their general purpose GPUs, and tossed out some lowest-binned chips to the mining market?